Keyword [Optical Flow] [FlowNet]
Zhu X, Xiong Y, Dai J, et al. Deep feature flow for video recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2349-2358.
该篇论文首先说明了Video Recognition的Problem:
- 直接将图像识别网络应用到视频frame上会产生非常大的计算量。例如,假设图像识别网络处理一张图片需要0.1s,而30 fps的视频而言,处理1s的视频内容需要3s,这显然是不具有可行性的。
因此,论文提出了一个用于Video Recognition的Framework Deep Feature Flow (DFF) (Figure 2):
- 仅仅将稀疏key frame输入Feature Network.
- 其他frame的特征图通过key frame的特征图进行propagation得到。
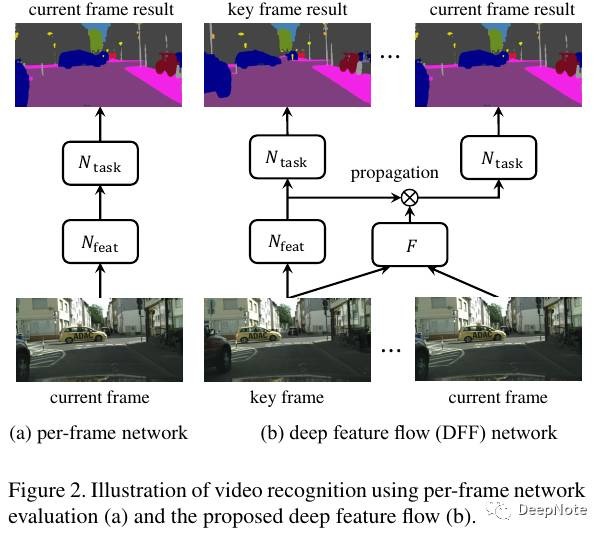
比较Figure 1中current frame feature maps和propagated feature maps:
- 将current frame输入Feature Network得到的特征图
- 对key frame特征图进行propagation得到的特征图
可以看出两类特征图基本类似。此外,可以明显看出Conv层中的#183 filter activate on车, #289 filter activate on 行人和狗。

通过Detection task实验(图1)可看出,DFF相对于Per-frame Network:
- 提高10倍速度。
- Accuracy仅仅从73.9%降低到69.5%.
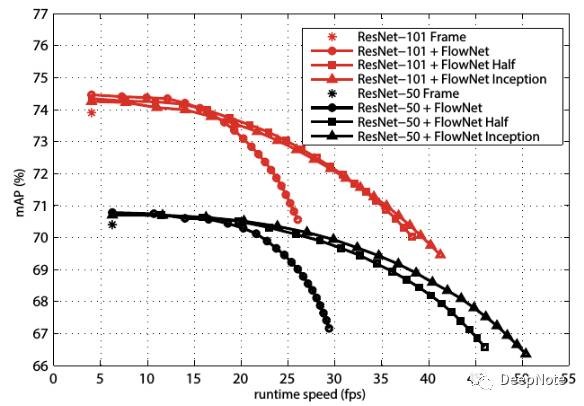
DFF能大幅度提升速度是因为:Flow estimation and feature propagation are much faster than the computationof convolutional features.
DFF结构包含3部分网络:
- Feature Network
- Flow Network
- Task Network
以及Inference和Training两个阶段
1. Feature Network
- 采用ResNet-50和ResNet-101 pre-trained on ImageNet Classification.

2. Task Network
- DeepLab for segmentation
- R-FCN for object detection
3. Inference
- Scale Function Better approximate the features the spatial warping may be inaccurate due to errors in flow estimation, object occlusion.
- 基于optical flow对key frame feature map进行bilinear interpolation 得到propagated feature map of current frame
- Key frame schedule
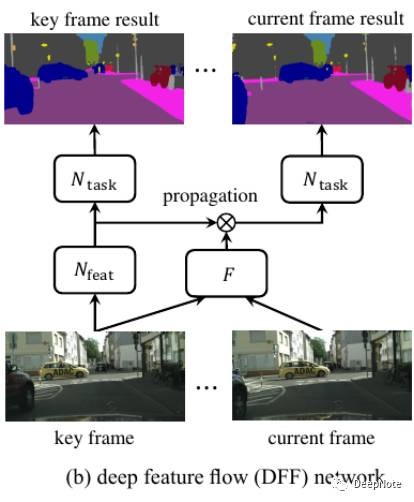
4. Training (图3)
- 选取labeled frame作为current frame(一些Dataset只有少数帧有ground-truth),随机选取附近的帧作为key frame:
- Current frame == key frame. 计算current frame loss(右半部分).
- Current frame != key frame. 计算key frame loss(左半部分).
- Inference阶段固定key frame, 顺序选取current frame.
5. Dataset
- ImageNet VID for object detection
- Cityscapes for semantic segmentation
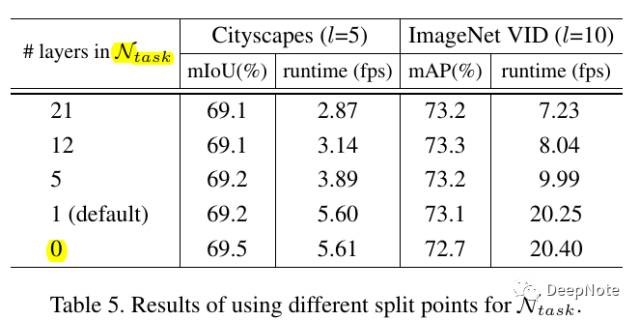
6. Task Network与Feature Network分割
- 论文做了一个实验,验证将Feature Network中最后多少层放入Task Network中性能最好。从Table 5中可以看出在两个网络完全分离的情况下,性能最好。
- DFF Framework的通用性,论文默认采用预留Feature Network中最后1层到Task Network中。
- Leaves some tunable parameters after the feature propagation, which could be more general.
7. Experiments Results
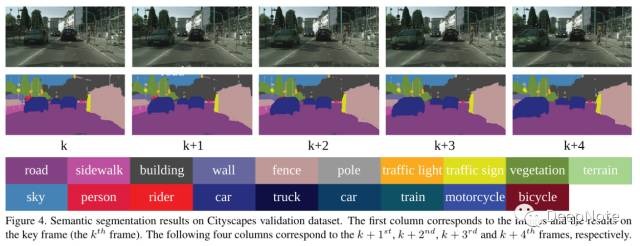

8. Future
- 论文提到未来将会在flow estimation和key frame scheduling两方面进行优化。
- 此外,论文结尾说,提出的DFF框架可能会成为一个新的研究方向。
个人认为在该框架上做大量的优化工作:
- 将ResNet换成DenseNet
- 将shortcut idea引入FlowNet,尝试提高计算速度和准确度
- 进行多次propogation对结果进行refined,提高准确度
- 修改Task Network,从而将很多其他图像处理任务(除Detection、Segmentation、Classification外)应用到视频流上。